在WWDC上,LLVM这个Section,基本是年年都有,前年写了篇文章介绍了下,今年继续吧。
本来想着今年有官方的中文字幕了,可喜可贺、可喜可贺,然而却是下面这样的情况:


看到这里我还是默默的切回了英文字母,这里就当给大家翻译翻译这篇Section。
一、C结构体中OC对象的ARC支持
Xcode10之前大家应该都知道ARC下struct里是不能放OC对象的,Xcode10中解除了这一限制,并且对于在栈上的这种结构体,可以做到完全自动的管理内存: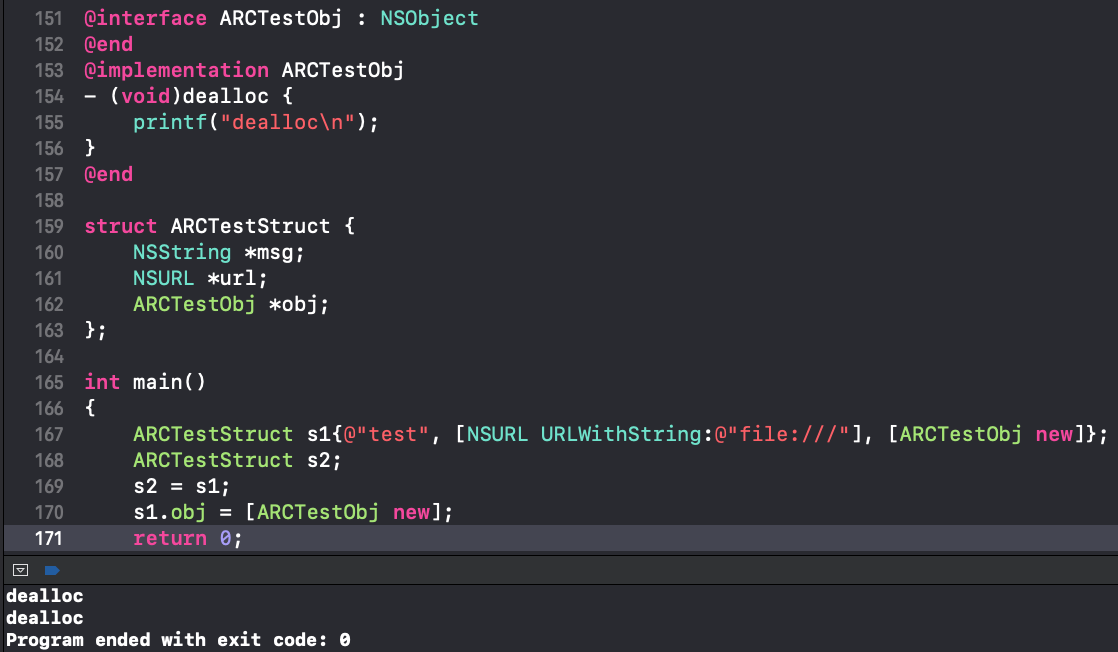
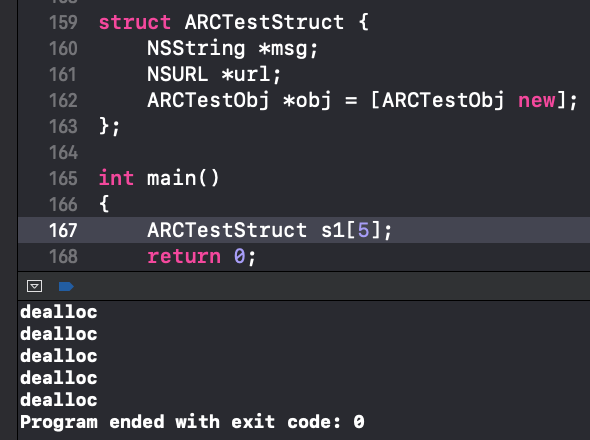
对于堆上的结构体则有一些不同,首先要用新加入的calloc代替malloc来申请内存,最后free掉之前要先置nil。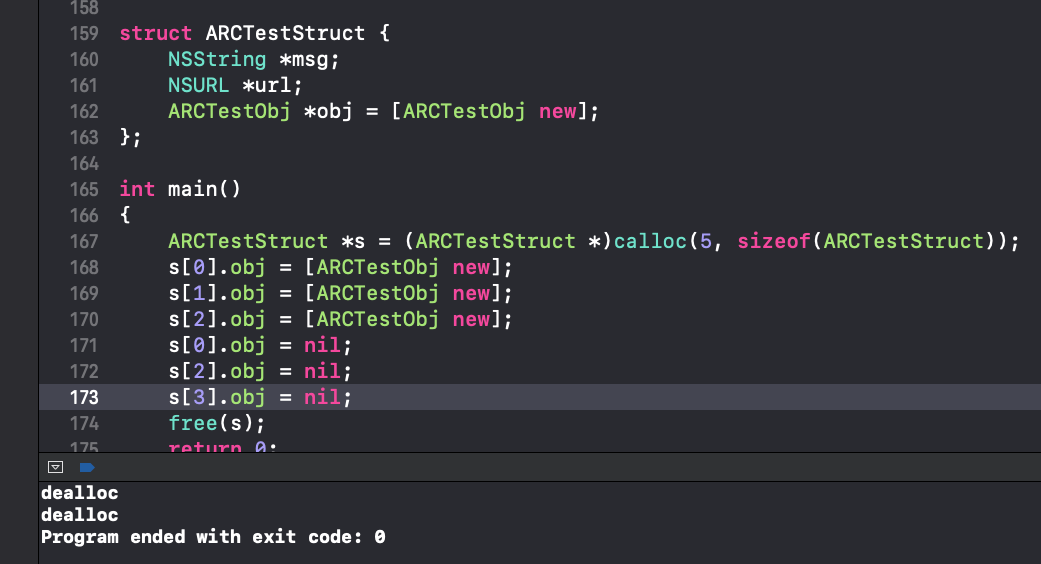
这里有几个问题:
- 首先是calloc完了之后要强转才能赋值,否则编译会报错(骗子啊,他ppt里是没有强转的)。我理解这个calloc的不同之处就是会把申请的内存都置0。
- 第二个是struct定义中的默认值,在这种情况下是失效的,上图中可以看到我把第四个元素也置空了,但是并没有多出一个dealloc,说明他本来就是个nil。
- 最后就是free掉之前要把所有struct里的OC字段都显式的置为nil,例子里第二个元素没有置空,所以最后的dealloc少了一个。
这种情况下感觉是个半成品,跟手动管理内存也没啥区别了,不过大部分情况下,我们也只需要用到栈上的结构体。
二、更强的代码诊断
这个部分大概也是年年讲的了,这里就挑两个讲讲:
OC中的NS_NOESCAPE
swift里闭包做参数,有escaping和non-escaping的区别。但是接口桥接给OC了之后,在OC中是没有办法知道是不是有escaping的。然后苹果就在OC里也加了一个NS_NOESCAPE的标识符,并且也引入了相关的警告。

Autorelease Pool外使用Autoreleasing的变量
直接来看一个比较隐蔽的错误,下面的代码为什么会Crash呢?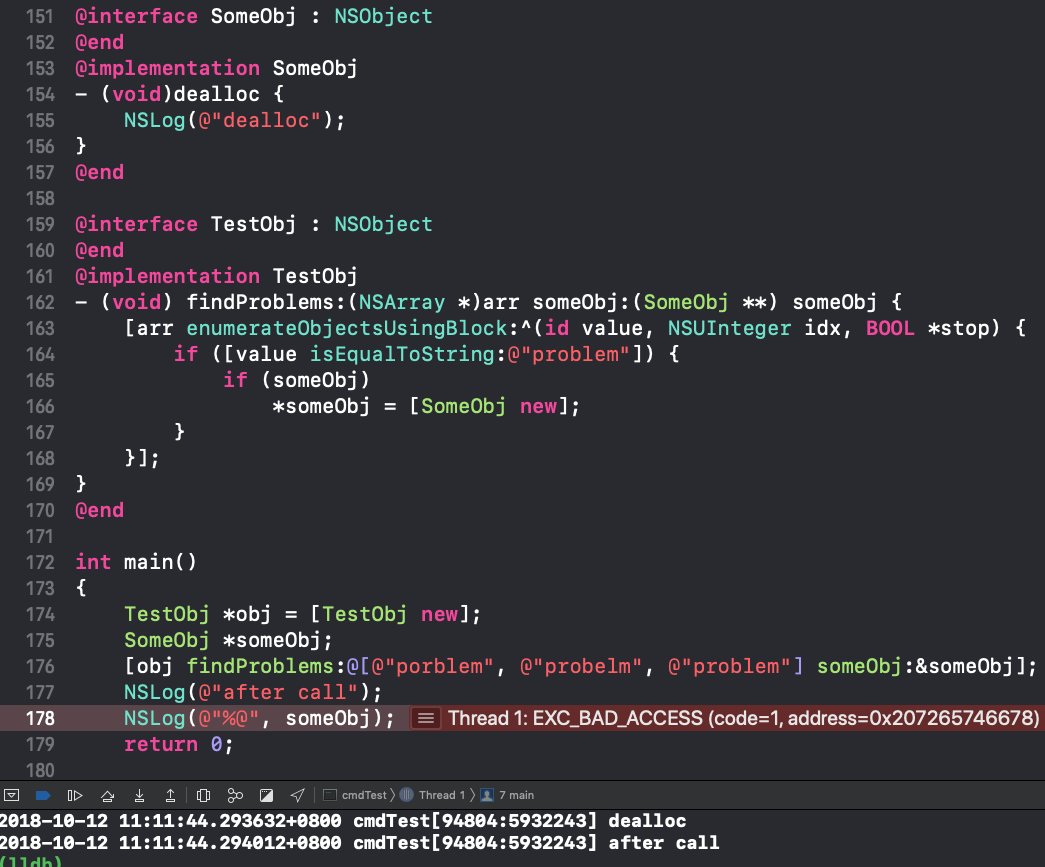
有两个关键因素导致了这个crash,并且大部分人都很难在看代码的时候意识到。
- 函数中的输出参数,默认是用__autoreleasing修饰的,即使你不写。
- enumerateXXX这一系列的容器接口,里面的实现是包了一层Autorelease Pool的。
这就导致了someObj在函数返回之前就已经dealloc了,后面再使用就会导致Use After Free的crash。从控制台的输出也可以看出来,dealloc是在after call之前输出的。
即使是这种比较隐蔽的情况,Xcode10中,静态分析也能指出这种错误了。
三、安全性提升
这个部分在Section中占了比较大的篇幅,不过主要也就讲了两个东西,都是关于防止栈上的写溢出导致的安全性问题,关于栈的基础知识讲解倒是挺多的……
Stack Protector
先贴一张函数调用栈的结构图,每一个栈桢对应一个函数调用的记录,存储着当前函数要用到的临时变量(栈变量)以及调用完成后要返回到哪里(返回地址)继续执行。
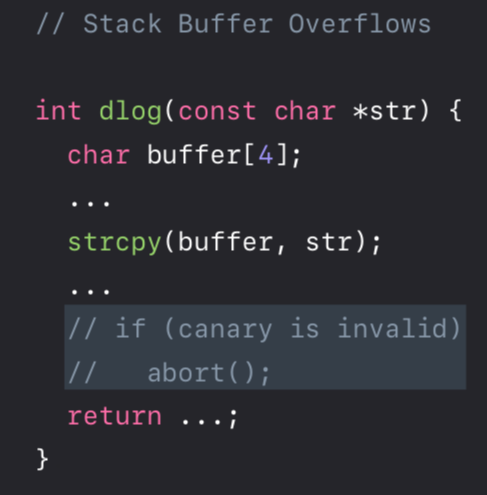
这里还涉及到一种很常见的攻击方法,栈溢出攻击。例如下面这个函数中使用的strcpy函数,它拷贝字符串时并不会判断原串的长度是否超过了目标buffer的长度。攻击者可以恶意的构造一个输入,来覆写当前函数的返回地址,达到控制程序执行流程的目的(跳过一些验证函数等)。
虽然现在使用这些函数会出警告,让你使用它们的安全版本(如strncpy),但是难免会有疏忽的时候。
新的编译器加入了Stack Protector这个特性来帮助我们防止这种攻击,原理如下图: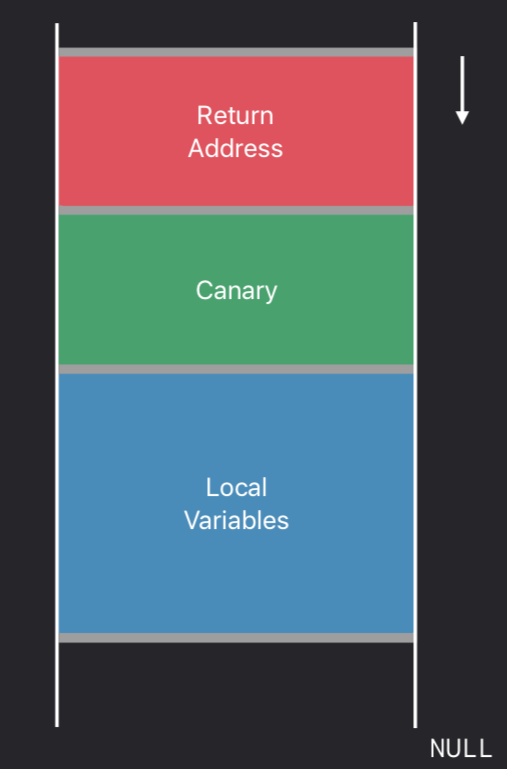
简单来说就就是在返回地址和栈变量中间加了一小段间隙,这里面会填充一些用于校验的数据,并且自动在函数return之前加入一段检测代码,检测间隙中的数据是否被修改了,如果检测失败,就会强制终止程序。
这个例子中,如果从栈变量的范围溢出去写返回地址,一定会修改到这块保护区。推测保护区的大小和内容都是会发生变化的,这样攻击者也没法构造一个使保护区不变的输入。
苹果说这个功能是默认打开的,然而我用他的示例代码并没有出现abort的情况,看反汇编也没有发现有相关的插入的代码在里面。
Stack Checking
这种保护措施是针对下面这种栈帧的大小也是由输入来控制的函数的。
一种情况是,攻击者传入一个非常大的len,导致这个栈帧的范围与堆的范围有重叠的部分,这样就相当于可以改写任意的堆上的对象了。
这里有一个前提就是,苹果的系统上,是允许申请一个像这样超大的栈上buffer的,甚至超出物理内存的大小也是可以的。因为系统只会在实际有读写操作时,才会给这段虚拟内存分配一个物理内存上的页,也就是说除了有操作的那一小块虚拟内存,它前后的大段虚拟内存都是不占用物理内存的。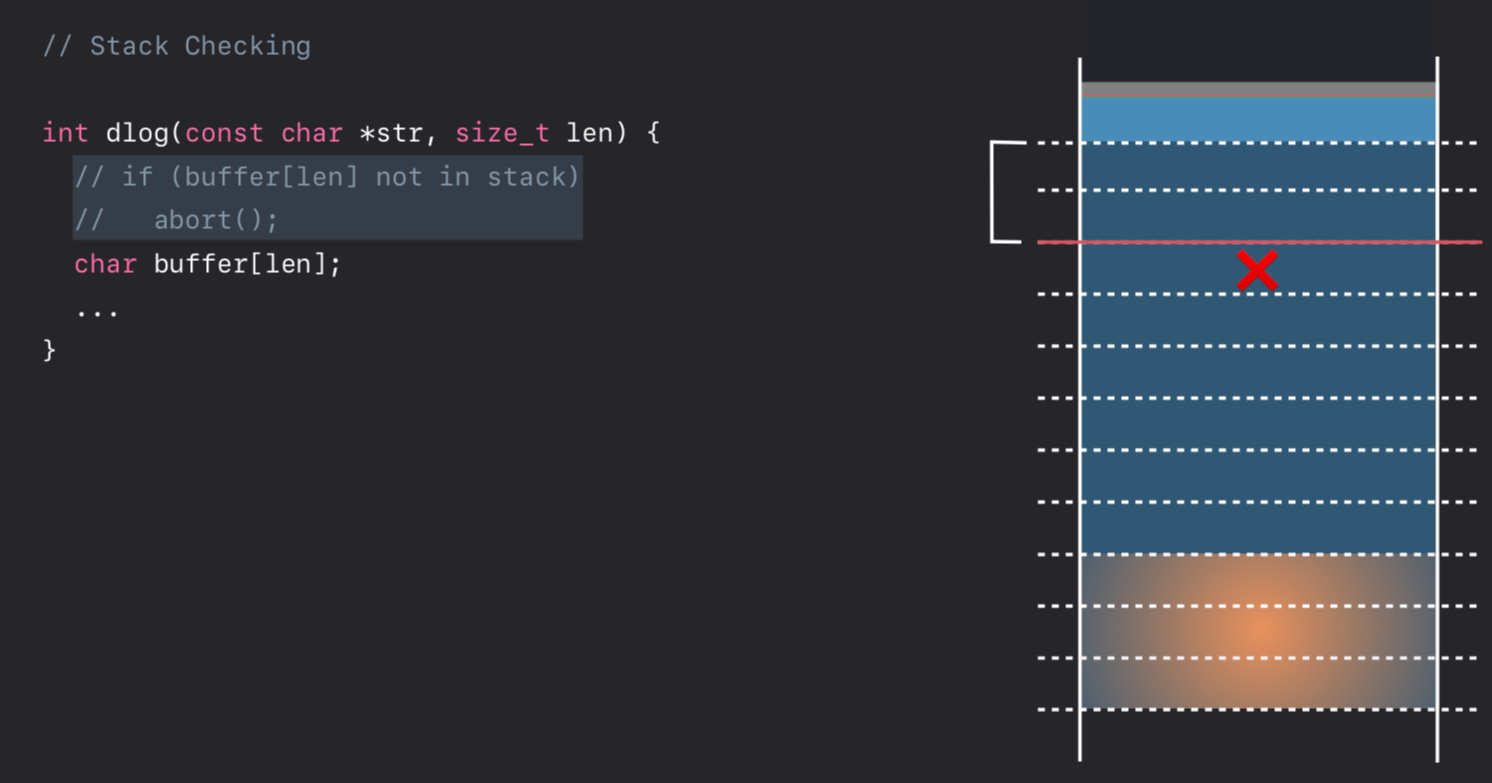
保护的方法也是类似的,在函数入口来检测栈帧的地址范围与堆是否有重叠,是的话也abort掉。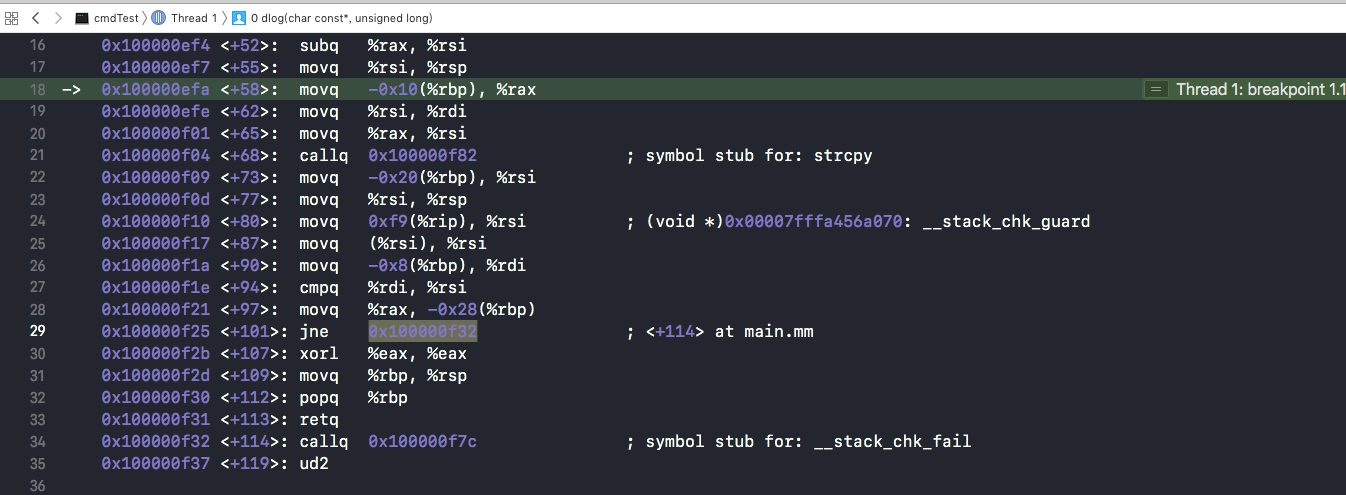
Debug下看反汇编,发现确实有相关的检测代码存在。
四、新的扩展指令集
由于没有这些新的设备,就没法实操了,直接上表格吧。
可以看到,移动和桌面平台上,都有SIMD相关的升级。
桌面端是支持了Intel六代U上增加的AVX512,寄存器宽了一倍,数量也多了一倍,达到32个512bit。
移动端则是在NEON指令集上增加了半精度浮点的支持,这样在位宽不变的情况下能多放一倍的数据进行并行操作,算是个小更新。据说主要是对机器学习有加成,因为机器学习需要的精度不高。
最后就是ARM v8.1中增加了原子操作相关的指令,在此之前ARM上的原子操作都是通过Load-link/store-conditional的方式实现的,虽然也是Lock Free的,但是通常需要四条指令。这会加速iOS上APP里用到的原子操作,我自己写项目的时候有时候也会用到,不过总感觉在移动端上,这个东西应该不会造成性能瓶颈。